写在开始
本教程仅供学习,若被他人用于其他用途,与本人无关
第二战-利用XHR
使用selenium虽然可以偷懒,但如果能直接找到XHR,则可以直接从中获取内容,且更为快速
(当然知乎的XHR返回的内容是没有加密的,否则。。。。)
什么是XHR
XHR即XML Http Request 的简写,AJAX 使用的
XMLHttpRequest的对象与服务器通信,使得网页能够异步动态地加载内容分析XHR
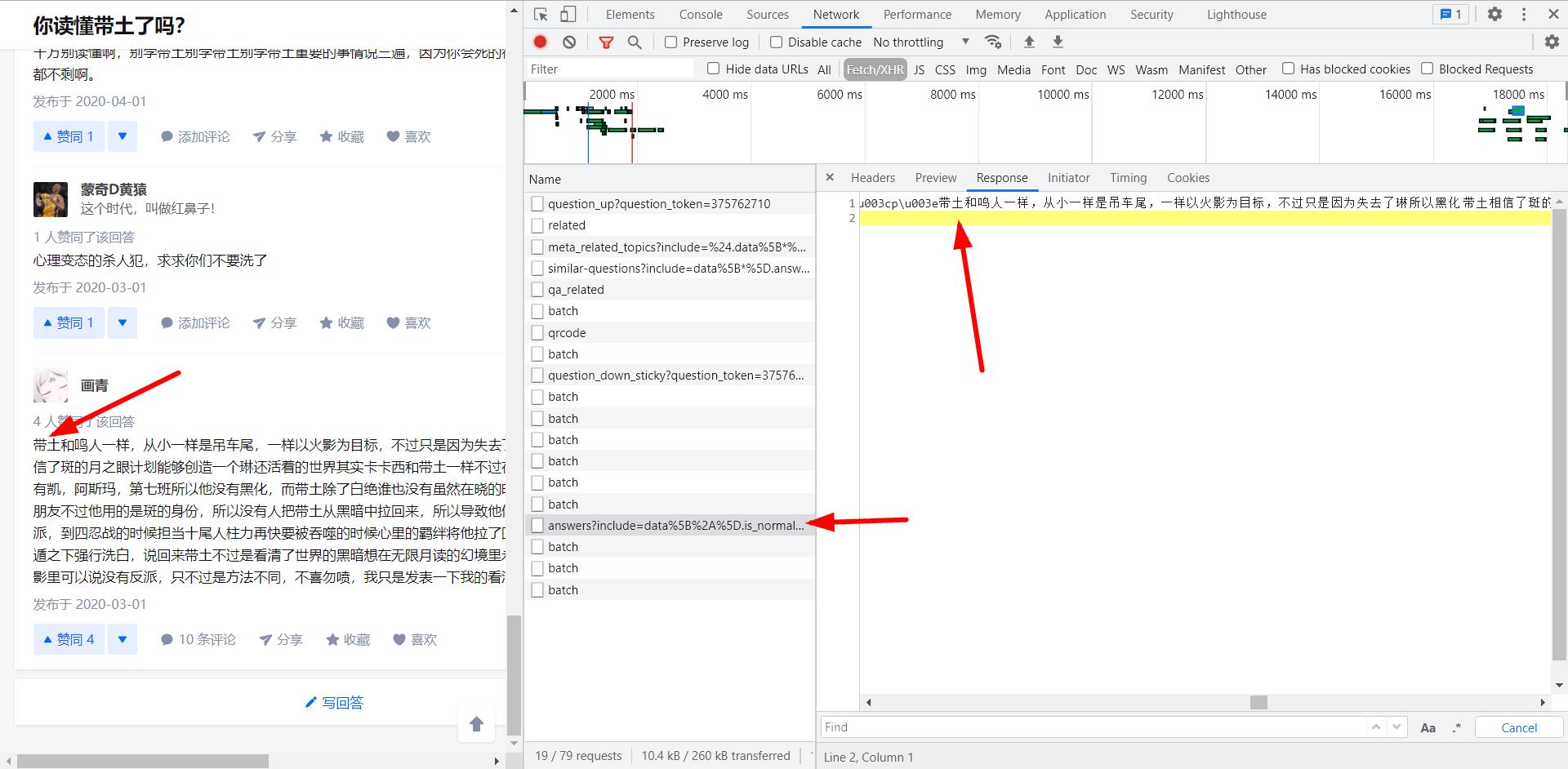
发现一个名为answer?include=data……的API内出现了我们想要的内容,分析其Request URL
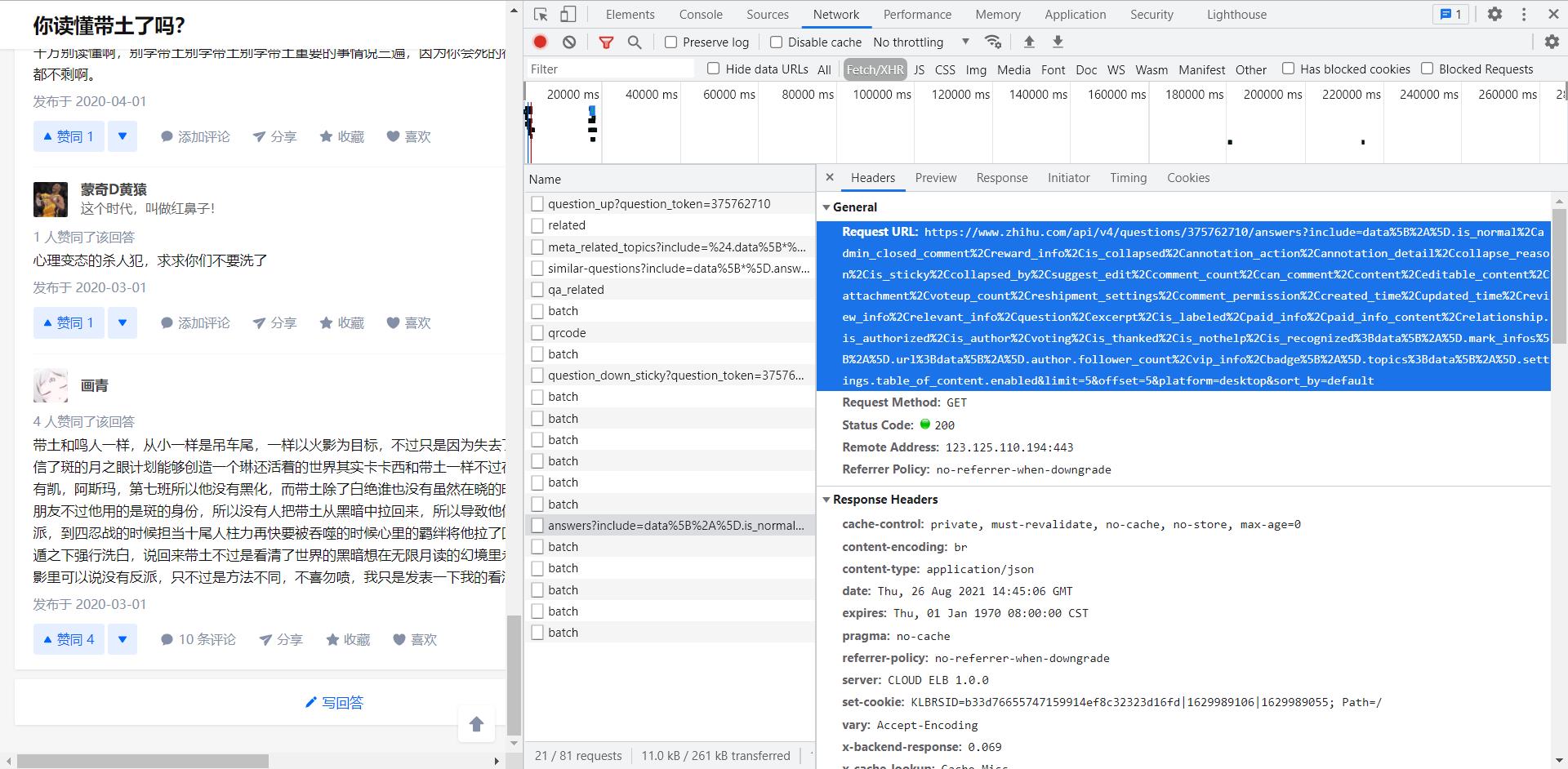
值得注意,里面的offset=参数是5的倍数,而questions/{}/answers?之间的是{question_id}
由此,我们分析得到了可以获取问题答案的XHR
1
同理,在点击展开评论后,我们也能分析得到获取评论的XHR:https://www.zhihu.com/api/v4/answers/1047398459/root_comments?order=normal&limit=20&offset=0&status=open
获取答案
通过requests.get获取数据,利用json.loads解析后(可以结合etree)找到各部分(答案ID,回答者,回答内容等等)数据
利用state保证一次连接的成功
利用
is_end = jsonAnswer['paging']['is_end']作为判断结束的标志利用
data['comment_count'] > 0判断改问题是否有获取评论的必要
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33def GetAnswers(question_id):
i = 0
while True:
url = f'https://www.zhihu.com/api/v4/questions/{question_id}/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset={i}&platform=desktop&sort_by=default'
state=1
while state:
try:
res = requests.get(url, headers=headers, timeout=(3, 7))
state=0
except:
continue
res.encoding = 'utf-8'
jsonAnswer = json.loads(res.text)
is_end = jsonAnswer['paging']['is_end']
for data in jsonAnswer['data']:
……
……
……
if data['admin_closed_comment'] == False and data['can_comment']['status'] and data['comment_count'] > 0:
GetComments(question_id,answer_id)
i += 5
if is_end:
break
time.sleep(1)打省略号的部分是需要用户自己选择需要的数据
例如answer_id:
str(data['id'])content:
''.join(etree.HTML(data['content']).xpath('//p//text()'))获取评论
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33def GetComments(question_id,answer_id):
j = 0
while True:
url = 'https://www.zhihu.com/api/v4/answers/{0}/root_comments?order=normal&limit=20&offset={1}&status=open'.format(
answer_id, j)
state=1
while state:
try:
res = requests.get(url, headers=headers, timeout=(3, 7))
state=0
except:
continue
res.encoding = 'utf-8'
jsonComment = json.loads(res.text)
is_end = jsonComment['paging']['is_end']
for data in jsonComment['data']:
……
……
……
for child_comments in data['child_comments']:
……
……
……
j += 20
if is_end:
break
time.sleep(1)多线程优化
(这里提醒一下,希望大家不要无限制地多开线程占用服务器资源)
go就是自己编写的爬取函数,questions是一个存储问题ID的队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24from threading import Thread
from queue import Queue
# 读取队列中问题ID,并运行函数
def run(queue):
while queue.empty() is not True:
num=queue.get()
print(f'开始爬取问题,ID为{num}')
go(num)
print(f'{num}号问题爬取完毕')
questions.task_done()
start = time.time()
# 构造线程
for index in range(10): # 10 个线程
thread = Thread(target=run, args=(questions,))
thread.daemon = True # 随主线程退出而退出
thread.start()
# 线程结束
questions.join()
end = time.time()
print(f'总耗时:{end - start}')
结语
不知道大家在爬取之前,是否注意到知乎遵循了robots协议(没有关注过的可以点击这个网址:https://www.zhihu.com/robots.txt)
为了不给网站的管理员带来麻烦,希望大家在爬取的时候能尽量遵循robots协议;若在学习过程中在不可避免地无法遵循robots协议,也尽量维持爬虫爬取频率与人类正常访问频率相当,不过多占用服务器资源
写在最后
技术是无私的,非常不舍得把我这个实战代码分享了出去,毕竟以我的爬虫技术,编写这么个知乎爬虫实战的代码还是很费劲的,花了很多心血,也踩了很多坑
希望大家能够多多支持大可,有什么问题都可以提交,我也会及时为大家解决。最后也欢迎大家光临我的小站 https://cheungducknew.github.io/
