关键词提取算法
TF-IDF算法
算法原理
TF-IDF(Term Frequency/Inverse Document Frequency),即词频-逆文档频率算法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。相关公式如下:
$TF_{W,D_i} = \frac{count(W)}{|D_i|}$
$IDF_W = \log \frac{N}{1 + \sum_{i=1}^N I(W,D_i)}$
$TF - IDF_{W,D_i} = TF_{W,D_i} \times IDF_W$
其中count(w)为关键词w的出现次数,|Di|为文档Di中所有词的数量,N为所有的文档总数,I(w,Di)表示文档Di是否包含关键词。
核心代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
321. def get_keywords(text):
2. # 统计词频
3. cnt = defaultdict(int)
4. for line in text:
5. for i in line:
6. cnt[i] += 1
7.
8. # 计算TF
9. tf = {}
10. for i in cnt:
11. tf[i] = cnt[i] / sum(cnt.values())
12.
13. # 计算IDF
14. idf = {}
15. paragraph = defaultdict(int) # 存储包含该词的段落数
16. for i in cnt:
17. for j in text:
18. if i in j:
19. paragraph[i] += 1
20.
21. n = len(text)
22. for i in cnt:
23. idf[i] = math.log(n / (paragraph[i] + 1))
24.
25. # 计算每个词的TF*IDF的值
26. tf_idf = {}
27. for i in cnt:
28. tf_idf[i] = tf[i] * idf[i]
29.
30. # 字典按值降序
31. res = sorted(tf_idf.items(), key=lambda x:x[1], reverse=True)# 利用 lambda 表达式取字典的值
32. return res
TextRank算法
由于TF-IDF算法需要事先准备语料库,不具备普遍性,因此我们可以选用更简洁有效的TextRank算法来做关键词提取。
算法原理
TextRank 算法基于图的排序算法,其基本思想来源于PageRank算法, 通过把文本分割成若干组成单元(单词、句子)并建立图模型,仅利用单篇文档本身的信息即可实现关键词提取。计算公式如下:
$WS(V_i) = (1-d) + d\times \sum_{V_j \in In(V_i)} \frac{W_{j i}}{\sum_{V_k \in Out(V_j)} W_{jk}} WS(V_j)$
其中WS(Vi)表示单元Vi的权重,d为阻尼系数,一般取0.85,Wji表示单元j和单元i的相似度,右侧求和表示每个相邻单元对当前单元的贡献程度,可以粗略认为小文本中的每个单元都是相邻的。核心代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
991. import numpy as np
2. import jieba
3. import jieba.posseg as pseg
4. import csv
5.
6.
7. class TextRank(object):
8. def __init__(self, sentence, window=5, d=0.85, iternum=1000):
9. """
10. :param sentence: 提供的文本
11. :param window: 窗口大小,这里取5
12. :param d: 阻尼系数,一般取0.85
13. :param iternum: 迭代次数,可以取1000
14. """
15. self.sentence = sentence
16. self.window = window
17. self.d = d
18. self.iternum = iternum
19. self.edge = {} # 记录节点的边
20.
21. # 分词
22. jieba.load_userdict('user_dict.txt') # 加载自定义字典
23. self.word_list = [s.word for s in pseg.cut(self.sentence) if len(s.word)>=2 and s.flag in ['n','nr','ns','nt','nz']] # n为名词
24. self.size = len(self.word_list)
25. self.set_size = len(set(self.word_list))
26. # print(self.word_list)
27.
28. #处理过程
29. self.getNodes()
30. self.getMatrix()
31. self.getW()
32.
33. #输出结果
34. # self.show()
35.
36.
37.
38. # 构建相邻节点,返回边集
39. def getNodes(self):
40. tmp_list = []
41. for idx, word in enumerate(self.word_list):
42. if word not in self.edge.keys():
43. tmp_list.append(word)
44. tmp_set = set()
45. low = idx - self.window + 1 if idx - self.window + 1>=0 else 0 # 下边界
46. high = idx + self.window if idx + self.window<self.size else self.size # 上边界
47. for i in range(low, high):
48. if i != idx:
49. tmp_set.add(self.word_list[i]) #添加窗口内相邻节点
50. self.edge[word] = tmp_set
51.
52. # 构建矩阵
53. def getMatrix(self):
54. self.matrix = np.zeros([self.set_size, self.set_size]) #初始化矩阵
55. self.word_idx = {} # 记录词的下标
56. self.idx_word = {} # 记录下标对应的词
57.
58. for i, v in enumerate(set(self.word_list)):
59. self.word_idx[v] = i
60. self.idx_word[i] = v
61. for key in self.edge.keys():
62. for w in self.edge[key]:
63. self.matrix[self.word_idx[key]][self.word_idx[w]] = 1
64. self.matrix[self.word_idx[w]][self.word_idx[key]] = 1
65. # 归一化
66. for j in range(self.matrix.shape[1]):
67. sum = 0
68. for i in range(self.matrix.shape[0]):
69. sum += self.matrix[i][j]
70. for i in range(self.matrix.shape[0]):
71. self.matrix[i][j] /= sum
72.
73. # 迭代,计算权重
74. def getW(self):
75. self.W = np.ones([self.set_size, 1])
76. for i in range(self.iternum):
77. self.W = (1 - self.d) + self.d * np.dot(self.matrix, self.W)
78.
79. # 输出结果
80. def show(self):
81. res = {}
82. for i in range(len(self.W)):
83. res[self.idx_word[i]] = self.W[i][0]
84. res=sorted(res.items(), key=lambda x: x[1], reverse=True)
85. # print(res)
86. with open('斗破苍穹.csv','w',encoding='utf-8') as f:
87. csv_writer = csv.writer(f)
88. csv_writer.writerow(["姓名", "权重"])
89. for name,w in res:
90. csv_writer.writerow([name, w])
91.
92.
93.
94. if __name__ == '__main__':
95. filename='斗破苍穹.txt'
96. with open(filename, 'r', encoding='utf-8')as f:
97. text = f.read()
98. tr = TextRank(text)
99. tr.show()
社交网络分析
- 通过jieba分词,结合自定义词典得到人名;
- 构建共现矩阵统计每一段中共现的人物,通过字典保存
1 | 1. def social_contact(file_name): |
社交网络可视化
NetworkX库
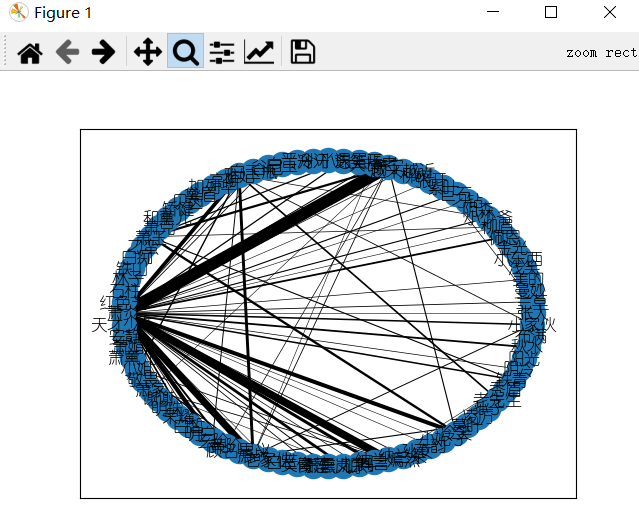
具体内容可以看我写的另一篇文章可视化之网络图
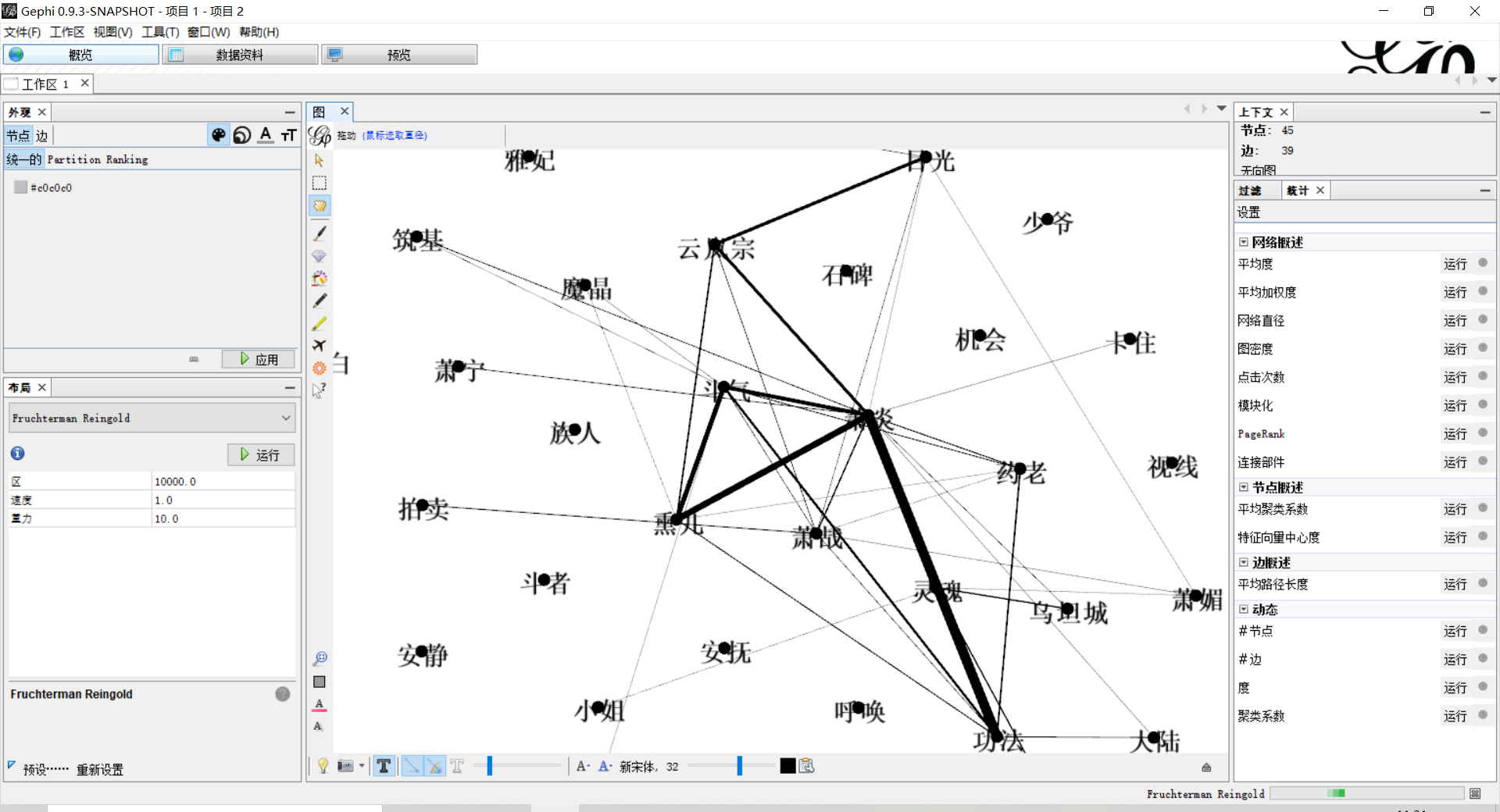
Gephi软件
Gephi软件有着强大的可视化功能。
通过导入节点表和边表,能够生成可更改的图结构图片,如下图所示
节点表和边表的生成,可以参考:
1
2
3
4
5
6
7
8
9
10
11
12
13import codecs
with codecs.open("node.txt", "a+", "utf-8") as f:
f.write("Id Label Weight\r\n")
for name, times in names.items():
f.write(name + " " + name + " " + str(times) + "\r\n")
with codecs.open("edge.txt", "a+", "utf-8") as f:
f.write("Source Target Weight\r\n")
for name, edges in relationships.items():
for v, w in edges.items():
if w > 3:
f.write(name + " " + v + " " + str(w) + "\r\n")
讲个小知识,为什么使用codecs库?
codecs包含了编码解码器的注册和其他基本的类,开发者还可以通过codecs提供的接口自定义编/解码方案
通过指定codecs.open中的encoding参数,进行编码/解码方式的选择
更多编码转换方案相关的信息,还可通过标准库中自带的编码库
encodings进行查询
参考信息:https://zhuanlan.zhihu.com/p/26720957
1 | 技术是无私的,非常不舍得把我这个实战代码分享了出去,希望大家能够多多支持大可,有什么问题都可以提交,我也会及时为大家解决。最后也欢迎大家光临我的小站 http://ducknew.cf/ |
