树状数组是一颗多叉树,而线段树是一颗平衡二叉树,两者多用于区间的操作
借用宫水三叶的总结:
数组不变,求区间和:「前缀和」、「树状数组」、「线段树」
多次修改某个数,求区间和:「树状数组」、「线段树」
多次整体修改某个区间,求区间和:「线段树」、「树状数组」(看修改区间的数据范围)
多次将某个区间变成同一个数,求区间和:「线段树」、「树状数组」(看修改区间的数据范围
这样看来,「线段树」能解决的问题是最多的,那我们是不是无论什么情况都写「线段树」呢?
答案并不是,而且恰好相反,只有在我们遇到第 4 类问题,不得不写「线段树」的时候,我们才考虑线段树。
因为「线段树」代码很长,而且常数很大,实际表现不算很好。我们只有在不得不用的时候才考虑「线段树」。
总结一下,我们应该按这样的优先级进行考虑:
简单求区间和,用「前缀和」
多次将某个区间变成同一个数,用「线段树」
其他情况,用「树状数组」
我来归纳一下:
| 数据结构\操作 | 区间求和 | 区间最大值 | 区间修改 | 单点修改 |
|---|---|---|---|---|
| 前缀和 | √ | × | × | × |
| 树状数组 | √ | √ | × | √ |
| 线段树 | √ | √ | √ | √ |
- 只用到区间求和:前缀和
- 区间求和+单点修改:树状数组
- 区间修改:线段树
基本概念
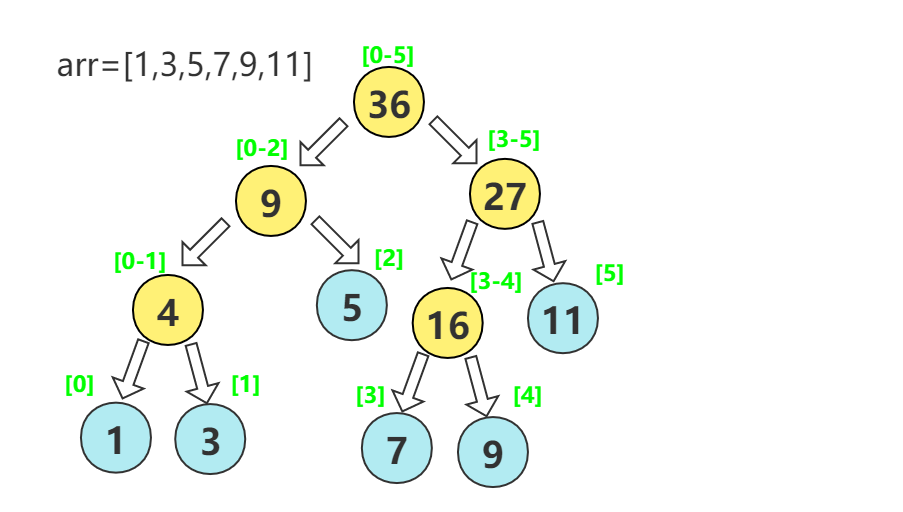
线段树是一棵平衡二叉树,母结点代表整个区间的和,越往下区间越小,叶节点长度为1,不可再分
线段树的每个节点都对应一条线段(区间),但并不保证所有的线段(区间)都是线段树的节点
节点 p的左右子节点的编号分别为2p和2p+1
假如节点p储存区间[a,b]的和,设$mid = \frac{l+r}{2}$那么两个子节点分别储存[l,mid]和[mid+1,r]的和
懒标记
区间更新是线段树的灵魂之一(我是这么理解的😀),其中懒标记是关键
当我们对区间修改时,如果类似于单点修改那样一个个修改,那么复杂度太高(O(nlogn)),显然不合适
这时我们对每个区间加一个懒标记,标志着这个区间是否进行了修改,如果进行了,那么它的子区间也要进行修改,并且把懒标记转给子结点
关键之处在于,我们只传递了懒标记,但并不会真的去修改这些子节点(而是在用到这个子节点的时候再修改)
懒标记的实质:拖延修改,能懒则懒
代码模板
考虑到线段树的复杂性,因此给出了一个可以运行和调试的代码,并且每个变量都采用了易于理解的全称,每个区间均为闭区间
由于使用了数组模拟,并且考虑到虚点(也就是没有区间长度的点)的存在,因此需要开4倍的空间,如果被卡空间复杂度,可以考虑换成节点模拟+动态开点
1 | def main(): |
区间更新:(这里放上了我自己总结的板子,每个人代码风格不一样,不用完全照搬)
1 | tree=[0]* 4*n |
无懒标记版本:
这个版本可以用来代替树状数组
tree=[0]*4*n
def build(p,s,t):
if s==t:
tree[p]=nums[s]
return
m=s+t>>1
build(2*p+1,s,m)
build(2*p+2,m+1,t)
tree[p]=tree[2*p+1]+tree[2*p+2]
def update(p,s,t,idx,val):
if s==t:
tree[p]=val
return
m=s+t>>1
if s<=idx<=m:
update(2*p+1,s,m,idx,val)
if m+1<=idx<=t:
update(2*p+2,m+1,t,idx,val)
tree[p]=tree[2*p+1]+tree[2*p+2]
def query(p,s,t,ql,qr):
if ql<=s and t<=qr:
return tree[p]
m=s+t>>1
res=0
if ql<=m:
res+=query(2*p+1,s,m,ql,qr)
if qr>m:
res+=query(2*p+2,m+1,t,ql,qr)
return res区域和检索 - 数组可修改
同样的题,昨天用树状数组写了一遍,今天可以用线段树来写了
1 | class NumArray: |
